
皆さんこんにちは、ITAです。
はじめに
今回は、手書き文字を認識するAIを作りました。私にはまだ難しいので一旦数字のみです。
画像の処理には OpenCV を使い、機械学習のモデルには TensorFlow + Keras を使います。
OpenCVとは?
OpenCVは、画像処理、解析をするためのオープンソースライブラリです。もともとはインテルが開発し、現在も世界中の開発者に広く使われています。
できることの一例
・画像の読み込み・表示・保存
・画像のリサイズや回転、フィルタ処理
・顔認識・物体検出
・画像から輪郭やエッジを抽出 などなど
今回は、手書き文字を画像ファイルで保存したあと、OpenCVを使ってその画像を読み込み、モデルに適した形に加工しました。
TensorFlowとKerasとは?
TensorFlow(テンソルフロー) は、Googleが開発した機械学習(ML)・深層学習(Deep Learning)用のライブラリです。
複雑なAIモデルを作成・学習・推論するためのフレームワークで、世界中の研究者・開発者が使っています。
Keras(ケラス) は、TensorFlowの上で動く「使いやすいインターフェース(API)」のようなものです。
なので今回もですが、普通はTensorFlowを使うときもKerasを通してモデルを作ります。
開発環境の準備
・Windows環境で実行
・Pythonバージョン:3.12(VScode使用)
・仮想環境を使ってライブラリを分離
手順
1.仮想環境の作成とライブラリのインストール
まず、仮想環境を構築します。仮想環境はモジュールの入れ替えや追加が容易で、かつ構築そして削除がスムーズに行えます。
以下のコードをコマンドプロンプトで一行ずつ行ってください。
# 仮想環境を作成
python -m venv kmnist-env
# 仮想環境を有効化(Windows)
.\kmnist-env\Scripts\activate
# 必要なライブラリをインストール
pip install tensorflow opencv-python matplotlib numpy今回は手書き数字の認識ですので「MNIST(エムニスト)」という有名な画像データセットを使います。
MNISTは、0〜9の手書き数字を集めた以下のような画像データ集です。
一枚の画像 = 28×28ピクセルのグレースケール画像
データ数 = 60,000枚(学習用)+10,000枚(テスト用)
このMNISTを使えば、数字認識AIが簡単に作れます。
2.手書き文字認識モデルの学習
・学習用コード(mnist_train.py)
まずは、MNISTの手書き数字画像を使って、分類モデルを学習させるコードを用意します。
以下のコードをわかりやすく mnist_train.py という名前で保存しましょう。ご自分の好きなものでも構いません。
import tensorflow as tf
from tensorflow.keras import layers, models
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# データを正規化(0〜1の範囲に)し、形を変える(28x28x1)
x_train = x_train.reshape(-1, 28, 28, 1).astype("float32") / 255.0
x_test = x_test.reshape(-1, 28, 28, 1).astype("float32") / 255.0
# モデルの定義(シンプルなCNN)
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation="relu", input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation="relu"),
layers.Dense(10, activation="softmax")
])
# モデルのコンパイル(最適化方法と損失関数などを設定)
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
# 学習(訓練データで5エポック学習)
model.fit(x_train, y_train, epochs=5, validation_data=(x_test, y_test))
# テストデータでの精度を評価
test_loss, test_acc = model.evaluate(x_test, y_test)
print("Test accuracy:", test_acc)
#モデルの保存
model.save("your_model.h5")ポイント解説!
| パート | 内容 |
|---|---|
load_data() | MNIST画像を読み込む(訓練用60,000枚/テスト用10,000枚) |
reshape | TensorFlowのモデルに合わせた形(28x28x1)に変換 |
Conv2D | 畳み込み層:画像の特徴(線や角)を抽出 |
MaxPooling2D | 特徴マップを小さくまとめて、処理を軽量化 |
Dense | 全結合層:特徴から分類を行う |
softmax | 出力を10種類のクラス(数字0〜9)に分類 |
fit() | 実際に学習する処理(5回繰り返す=5エポック) |
| .h5 | 学習済みのニューラルネットワーク構造と重みがすべて詰まったファイルとして保存 |
3.自分で書いた文字画像を使って予測する
① 手書き画像を用意
・手書きの「0〜9」の数字を描く(背景白、文字黒がBEST,精度が上がります)
・サイズは 28×28ピクセルのPNG画像がBEST(大きかったり、JPEGでも可。後にリサイズする)
・ファイル名は例として test.png にしておきます
②画像を読み込み&処理&数字を予測するコード
以下のコードを process.py などで保存しましょう。(お好きな名前でOK)
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import load_model
# 学習済みモデルの読み込み
model = load_model("your_model.h5")
# 画像の読み込み(グレースケール)
img = cv2.imread("test.png", cv2.IMREAD_GRAYSCALE)
# 画像を28x28にリサイズ(元画像が28x28ならそのままOK)
img_resized = cv2.resize(img, (28, 28))
# 画像を反転(背景白・文字黒 → 背景黒・文字白)
img_inverted = cv2.bitwise_not(img_resized)
# 画像を正規化(0〜1の範囲に)
img_normalized = img_inverted / 255.0
# 形を (1, 28, 28, 1) に変換(モデル入力形式に合わせる)
img_input = img_normalized.reshape(1, 28, 28, 1)
# モデルで予測
prediction = model.predict(img_input)
predicted_label = np.argmax(prediction)
# 結果表示
plt.imshow(img_resized, cmap="gray")
plt.title(f"Predicted Label: {predicted_label}")
plt.show()
print("予測された数字:", predicted_label)③実行
ターミナル(仮想環境上)で②のコード(process.py)を実行します。
python process.py出力はこんな感じになります。
予測された数字: 2やってみた
以上の手順を実際にやってみました。
手書き画像↓ リサイズ、グレースケール、白黒反転後↓
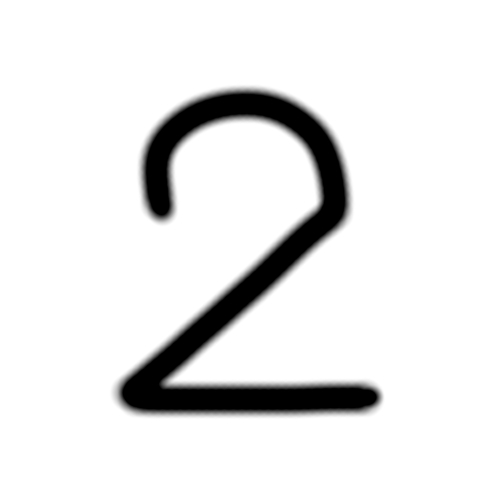
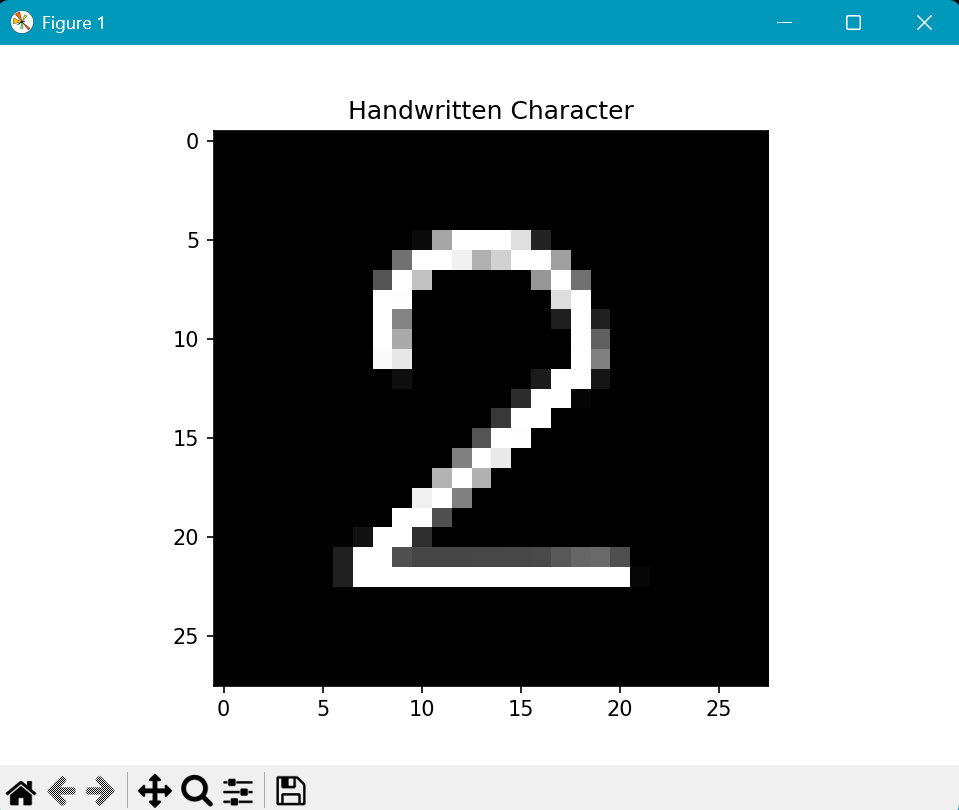
実行結果↓

正しく認識できました!
まとめ
手書き文字認識の世界は、シンプルに見えてとても奥が深いものです。
今回はその入り口として「数字」の認識にチャレンジしました。
画像処理の基本や、AIモデルを使った予測の流れを一通り体験できたと思います。
次のステップとしては、
- 自分で集めた手書きデータで学習する
- もっと複雑なひらがな、漢字に挑戦する
- 精度を上げるためにモデルを改良する
自分だけの手書き認識AIを育てていく過程は、とても楽しいです!


コメント